THC Technologies Corporation develops proprietary VoiceVantage™ voice verification technology, which either confirms or denies a claimed identity on the basis of voice characteristics. These unique features consist of cadence, pitch, tone, harmonics, and shape of larynx. The image below shows how characteristics of voice actually involve much more of the body than just the mouth.

The Voice Verification Process
There are two basic processes in a voice verification system, first, enrollment and then, identity verification. Enrollment creates a reference voiceprint for comparison in the future. Typically the enrollment process takes less than thirty seconds for a user to complete. Verification is the process of comparing a live voice sample to the previously enrolled voiceprint. Verification includes end-pointing, analysis, comparing and scoring.
Enrollment
The system will ask the user to say a phrase, for example, the word "Lockbox." The computer represents the phrase graphically as shown below. Although the signal looks as if it starts and stops three times, it is really all part of the same phrase. For VoiceVantage's™ voice verification technology, the process of finding the beginning and ending of a phrase is the fundamental first step in the voice verification process. Because a person's voice varies every time a particular phrase is said, it is a proven technique to have a person repeat a phrase 2 or 3 times, creating 2 or 3 signal reference files. It is all of these files together that are referred to as a voiceprint.
End-Pointing
As the first part of the verification process, End-Pointing is the foundation on which the other analyses take place. VoiceVantage's™ technology uses a technique based on the amount and timing of energy in the signal to find the beginning and ending of the phrase being analyzed. While it is possible to analyze the whole speech signal, there is better information available through analyzing the speech in finer detail. This finer detail is found in a frame.
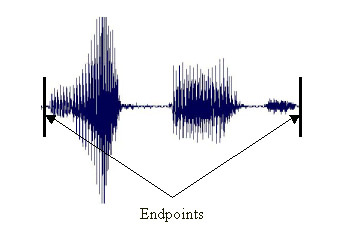
The phrase/word "LockBox"
Frames
Note the difference between the complete signal and a 30 millisecond (ms) slice. A complete signal has an overall pattern, as well as a much finer structure, called the frame. This frame is the essence of voice verification technology. It is these well-formed, regular patterns that are unique to every individual. These patterns are created from the size and shape of the physical structure of a person's vocal tract. Since no two vocal tracts are exactly the same, no two signal patterns can be the same.
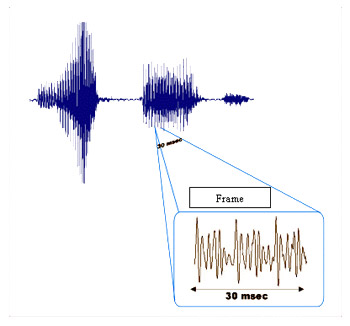
Analysis
The second step in the verification process is to slice the signal into 30 ms frames and analyze each resulting frame. In order to get even more information from the analysis the frames are actually overlapped like shingles on a roof, 30 ms frames beginning every 10 ms. In two seconds, rather than getting only sixty-seven frames, there are two hundred to analyze and compare. Using a technique called LPC Cepstral Analysis, VoiceVantage's™ technology computes a set of numbers that represent the physical characteristics of the vocal tract based on the information in the frame. Then, VoiceVantage's™ technology puts the information from all of the frames together and adds additional information for administrative purposes to create a reference file. These files are then stored in the database and associated with the user.
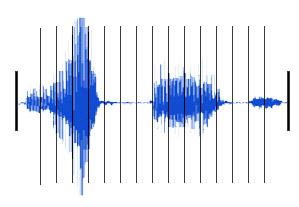
Comparing and Scoring
The enrollment and verification processes are identical up to the creation of a signal reference file. The signal reference file created during verification is compared against each rendition of the phrase stored in the database, finding the best match with the multiple reference signal files. Then, the process calculates the difference between the file being presented and the file in the database to create a similarity or confidence score. Both the comparing and scoring are achieved using a method called Dynamic Time Warping, DTW. The 'live' speech is compared to each of the stored versions of that phrase and the best score is identified. That score is converted to a number between 0 and 100 with 100 being a perfect match. This confidence score can then be compared to a threshold value to decide to accept or reject the speaker.